





Product request
You are looking for a solution:
Select an option, and we will develop the best offer
for you


IPTV-Plattform von Anfang an fehlertolerant planen
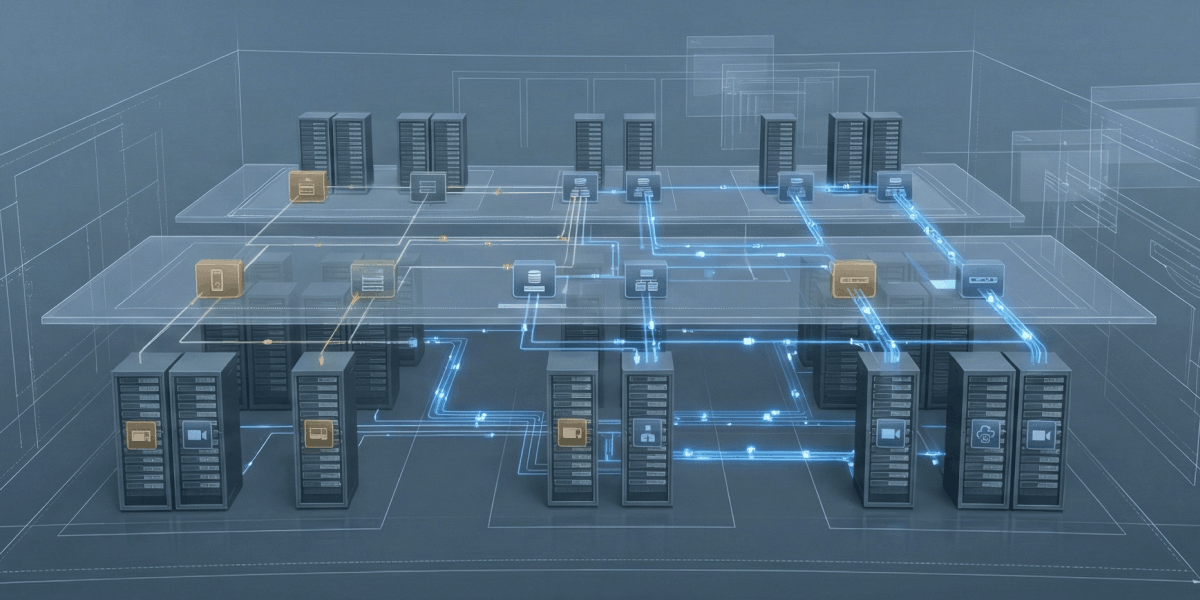
IPTV ist längst keine experimentelle Technologie mehr. Für Abonnenten ist es ein Basisdienst, der so zuverlässig funktionieren muss wie Strom aus der Steckdose. Jeder Ausfall führt sofort zu einer negativen Nutzererfahrung, Abwanderung und Druck auf den Betreiber. Deshalb ist Fehlertoleranz heute kein „Zusatzfeature“, sondern die Grundlage einer resilienten IPTV-Architektur.
Das Problem ist, dass viele Projekte mit Funktionalität und schneller Markteinführung beginnen, während Stabilität erst später berücksichtigt wird. Doch eine Plattform, die nicht für Ausfälle, Skalierung und kontrollierte Degradation ausgelegt ist, wird zwangsläufig an ihre Grenzen stoßen. Architektonische Fehler in einem Live-System zu beheben, ist teuer und riskant – daher muss ein fehlertolerantes IPTV-Design vom ersten Tag an eingeplant werden.
Ausfälle als Normalzustand, nicht als Ausnahme
Jedes verteilte System wird früher oder später mit Ausfällen konfrontiert: Festplatten fallen aus, Netzwerkverbindungen brechen ab, Knoten werden überlastet, menschliche Fehler passieren. Die Frage bei der Störungsbewältigung im IPTV lautet nicht, ob ein Ausfall eintreten wird, sondern wie sich das System verhält, wenn es dazu kommt. Eine ausgereifte IPTV-Plattform geht davon aus, dass Ausfälle ein normaler Zustand der Umgebung sind.
Die Architektur sollte Degradation statt Zusammenbruch unterstützen. Wenn ein Dienst nicht verfügbar ist, sollte der Nutzer weiterhin die Benutzeroberfläche, einige Kanäle und das Archiv sehen. Selbst eine eingeschränkte Funktionalität reduziert Frustration erheblich und verschafft dem Betreiber Zeit zur Wiederherstellung.
Komponententrennung als Grundlage der Resilienz
Monolithische Lösungen lassen sich einfacher starten, sind jedoch bei Ausfällen anfälliger. Eine moderne IPTV-Plattform sollte aus unabhängigen Komponenten bestehen: Billing, Middleware, EPG, CDN, DRM und Analytics. Moderne Redundanzplanung für Betreiber betont, dass jede dieser Komponenten autonom arbeiten und über Backup-Instanzen verfügen muss.
Dieser Ansatz für die Infrastruktur von IPTV-Betreibern ermöglicht die Isolierung von Problemen. Beispielsweise sollte ein Ausfall im Empfehlungssystem die Kanalwiedergabe nicht beeinträchtigen. Eine Überlastung des Portals darf Set-Top-Boxen nicht stören. Je schwächer die Kopplung zwischen den Modulen, desto höher ist die Wahrscheinlichkeit, dass die Zuverlässigkeit des IPTV-Dienstes erhalten bleibt und die Plattform auch unter ungewöhnlichen Bedingungen weiter funktioniert.
Daten als verletzlichstes Gut
Inhalte können neu kodiert, Dienste neu gestartet werden, doch verlorene Daten lassen sich oft nicht wiederherstellen. Für IPTV ist dies besonders kritisch in Bezug auf Benutzerkonten, Abonnements, Wiedergabeverlauf und Archivaufzeichnungen. Bei der Planung und dem Design einer IPTV-Plattform ist es wichtig, im Voraus festzulegen, welche Daten „golden“ sind, und einen mehrstufigen Schutz sicherzustellen.
Es geht nicht nur um Backups, sondern auch um Echtzeit-Replikation, Geo-Verteilung und das Testen von Wiederherstellungsszenarien. Um fehlertolerantes Streaming zu gewährleisten, sollte das System regelmäßig „Katastrophen“ wie Rechenzentrumsausfälle, Cluster-Verlust oder Speicherkorruption proben. Ohne solche Tests bleibt Fehlertoleranz nur Theorie.
Skalierung ohne Schmerzen
Wachstum der Abonnentenzahl ist wünschenswert, aber auch riskant. Eine Plattform ohne Risikomanagement für IPTV-Dienste oder ohne horizontale Skalierbarkeit beginnt genau im Moment des Erfolgs zu „reißen“. Im IPTV äußert sich das in langsamen Benutzeroberflächen, Unterbrechungen der Streams und Autorisierungsproblemen.
Eine durchdachte Architektur geht davon aus, dass jede Systemebene im Rahmen einer Multi-Node-IPTV-Bereitstellung erweitert werden kann: CDN, Middleware, Datenbanken, API-Dienste. Entscheidend ist, dass dies ohne Dienstunterbrechung geschieht. So werden Spitzenlasten – etwa bei Sportereignissen, großen Updates oder Marketingkampagnen – nicht zum Stresstest für das gesamte Unternehmen.
Monitoring als Teil des Produkts
Fehlertoleranz ist ohne Transparenz unmöglich. Monitoring der IPTV-Infrastruktur ist unerlässlich und bedeutet, dass die Plattform ihren eigenen Zustand meldet: Metriken, Logs, Warnmeldungen, nutzerseitige Fehler. Dies ist kein internes Tool, sondern Teil des Produkts, das die Servicequalität direkt beeinflusst.
Wenn ein Betreiber Degradation erkennt, bevor Abonnenten sie bemerken, führt ein proaktiver Ansatz zur Fehlererkennung zur Optimierung der IPTV-Verfügbarkeit. Automatisierte Szenarien – Neustart von Diensten, Umschalten des Datenverkehrs, Isolierung problematischer Knoten – machen aus Vorfällen Routineereignisse statt Katastrophen.
Wo IPTV-Architekturen am häufigsten scheitern – und welche Praktiken die Plattformresilienz wirklich verbessern
Instabilität in IPTV-Projekten entsteht meist dort, wo aus Gründen des schnellen Markteintritts architektonische Kompromisse eingegangen werden: engere Kopplung zwischen Komponenten und versteckte Single Points of Failure. In der Praxis sieht das wie ein „bequemer Monolith“ oder eine „einzelne Datenbank / einzelner Middleware-Knoten“ aus, der schwer zu skalieren ist und bei einem Ausfall die gesamte Servicekette mit sich zieht. Branchenrichtlinien zur Zuverlässigkeit empfehlen ausdrücklich, Systeme ohne Single Points of Failure zu entwerfen und Last sowie Komponenten über unabhängige Ausfalldomänen (Zonen/Regionen) zu verteilen – andernfalls führt jeder Infrastrukturvorfall zu einem vollständigen Dienstausfall.
Probleme, die nach einem Jahr Betrieb „an die Oberfläche“ kommen, sind meist bereits in der Phase der ersten Architekturentscheidungen und des initialen Produktionsstarts angelegt – wenn vollständige Observability noch fehlt, Ziel-SLOs und Latenzbudgets nicht definiert sind und Degradations- sowie Disaster-Recovery-Szenarien nicht geprobt wurden. In verteilten Systemen sind Kaskadeneffekte besonders gefährlich: Ein langsamer oder instabiler Dienst überlastet andere durch Wiederholungsversuche und Timeouts. Zur Prävention setzt die Branche auf Muster wie den Circuit Breaker, der Anfragen an eine instabile Abhängigkeit stoppt, sobald Fehlerschwellen überschritten werden, und so die Ausbreitung des Problems verhindert.
Bei der Plattformgestaltung unterschätzen Betreiber häufig nicht den „Ausfall eines einzelnen Servers“, sondern komplexere Szenarien: Netzwerkdegradation, partielle Ausfälle von Abhängigkeiten, Konfigurationsfehler, Ressourcenerschöpfung und „Gray Failures“, bei denen ein Dienst technisch läuft, aber die Last nicht mehr bewältigt. Deshalb setzen reife Zuverlässigkeitspraktiken zunehmend auf Chaos Engineering – die kontrollierte Injektion von Fehlern in Vorproduktions- oder begrenzten Produktionsumgebungen –, um das Verhalten des Systems unter realen Bedingungen zu beobachten und seine Wiederherstellungsfähigkeit zu trainieren.
Der Übergang von lokalem IPTV zu einem hybriden IPTV/OTT-Modell verschiebt die Prioritäten: Die Rolle von ABR-Delivery, der CDN-Schicht und Failover-Mechanismen „auf dem Weg zum Zuschauer“ nimmt zu. Resilienz wird nicht mehr allein durch den Schutz des „Kerns“ erreicht – sie erfordert eine zuverlässige Edge-Auslieferung sowie das Umschalten zwischen Delivery-Providern (Multi-CDN) und Qualitätskontrolle auf Stream-Ebene. Die grundlegende Logik von CDN – geo-verteilte Auslieferung näher am Nutzer – zielt darauf ab, Latenz zu reduzieren und Resilienz zu erhöhen, während Multi-CDN allgemein als Zuverlässigkeitspraxis durch Provider-Redundanz gilt.
Aus Sicht der Metriken lassen sich Probleme am besten nicht durch Dutzende lokaler Indikatoren, sondern durch aussagekräftige Kennzahlen vorhersagen, die mit dem tatsächlichen Nutzererlebnis verknüpft sind. Im SRE-Ansatz von Google sind dies die vier „goldenen Signale“ des Monitorings: Latenz, Traffic, Fehler und Sättigung – sie zeigen schnell, wo Degradation beginnt und was das System begrenzt. Gleichzeitig entsteht häufig eine „Illusion der Kontrolle“ durch Metriken um der Metriken willen (zum Beispiel durchschnittliche CPU-Auslastung ohne Kontext, „gemittelte“ Latenzen ohne Perzentile oder schöne Dashboards ohne Bezug zur User Journey).
Das Mindestset an Praktiken zur Vorbereitung auf ein 5–10-faches Wachstum reduziert sich in der Regel auf einige Kernprinzipien: Beseitigung von Single Points of Failure durch Redundanz und Verteilung über Zonen/Standorte, Automatisierung der Wiederherstellung, Isolation von Ausfalldomänen und Sicherstellung von Observability durch die „goldenen Signale“. Diese Ansätze spiegeln sich direkt in den Zuverlässigkeitsempfehlungen großer Cloud-Plattformen wider und können als Referenzmodell für das Design von IPTV/OTT-Architekturen unabhängig vom konkreten Technologie-Stack dienen.
Von Resilienz zu Vertrauen
Eine fehlertolerante IPTV-Plattform ist keine Sammlung teurer Technologien, sondern eine Denkweise. Sie beginnt mit der Akzeptanz, dass Ausfälle unvermeidlich sind, und endet mit einem System, das in einer realen, unvollkommenen Welt bestehen kann. Strategien zur Streaming-Kontinuität sollten sich nicht nur auf Server und Cluster konzentrieren, sondern auch auf Prozesse, Kultur und die Reife des Teams.
Indem ein Betreiber von Anfang an mit Blick auf Over-the-Air-Failover plant, investiert er nicht nur in Stabilität, sondern auch in das Vertrauen von Abonnenten und Partnern. In einer Welt, in der Inhalte überall verfügbar sind, werden Resilienz und Zuverlässigkeit des IPTV-Netzwerks zu den Faktoren, die einen professionellen Dienst von einer temporären Lösung unterscheiden.
Recommended

Wie man eine Staging-Umgebung für das Testen von IPTV-Updates richtig aufbaut
Jede Aktualisierung in einem IPTV-Ökosystem wirkt sich auf mehr als nur eine Komponente aus und kann Authentifizierung, Kanalstart, EPG, VoD, DRM und Netzwerkstabilität beeinflussen.

B2B-Nischen für IPTV: von Hotels bis Corporate TV
IPTV geht zunehmend über die Grenzen des klassischen Betreibergeschäfts und des Consumer-TV hinaus. Für das B2B-Segment – von Hotels und Business-Centern bis zu medizinischen Einrichtungen und Unternehmensbüros – wird IPTV zu einem Werkzeug für Service, Kommunikation und Aufmerksamkeitsmanagement.

Single Sign-On im IPTV: Zugriff vereinfachen, ohne die Sicherheit zu beeinträchtigen
Der IPTV- und OTT-Markt hat sich längst von der Vorstellung verabschiedet, dass Inhalte nur auf einem einzigen Bildschirm konsumiert werden.
